

Googleは現地時間3日、最新のAIモデル「Gemma 4 12B」を発表しました。
Gemma 4とは?
Gemma 4 12Bについて説明する前にGemma 4について説明しておきましょう。
Gemma 4は、Google DeepMindが開発した最新AIモデルのファミリーです。商用利用が無料でありながら、クラウド上における最上位クラスのAIを個人のPCやスマートフォンなどのローカル環境で実行することができる点が最大の特徴です。
Gemma 4 12Bの特徴
さて、前置きが長くなりましたが、Gemma 4 12Bについて説明します。
「Gemma 4 12B」は端末でのエッジ処理に向けた軽量なE4Bと、高度な26B MoE(Mixture of Experts)の中間に位置します。
RAM使用量を抑えつつ、強力な機能を凝縮しており、ネイティブオーディオ入力を搭載した初のミドルサイズとしての特徴も持ち合わせています。
Gemma 4 12Bの独自性と注目すべき点
Gemma 4 12Bの独自性についてGoogleはブログで以下のように説明しています。
- Novel unified architecture: No multimodal encoders. The vision and audio inputs flow directly into the LLM backbone.(和訳:革新的な統合アーキテクチャ:マルチモーダルエンコーダーは不要。画像と音声の入力はLLMバックボーンに直接送られます。)
- Drafter-ready: Gemma 4 12B comes equipped with Multi-Token Prediction (MTP) drafters to reduce latency.(和訳:ドラフター対応:Gemma 4 12Bは、レイテンシを低減するマルチトークン予測(MTP)ドラフターを搭載しています。)
- Advanced reasoning: Benchmark performance nearing our 26B model, unlocking powerful multi-step reasoning and agentic workflows.(和訳:高度な推論:ベンチマーク性能は26Bモデルに匹敵し、強力なマルチステップ推論とエージェント型ワークフローを実現します。)
- Laptop ready: Small enough to run locally with just 16GB of VRAM or unified memory.(和訳:ラップトップ対応:16GBのVRAMまたは統合メモリでローカル環境でも動作可能な小型設計。)
- Open and accessible: Released under an Apache 2.0 license with support across the developer ecosystem.(和訳:オープンでアクセスしやすい:Apache 2.0ライセンスでリリースされ、開発者エコシステム全体でサポートされています。)
原文:(The Keyword)、翻訳:Google翻訳
特に注目すべき点は、16GBクラスののRAM(またはユニファイドメモリ)を備えた環境でローカル実行を視野に入れつつ、26Bモデルに迫る性能を示している点、そして画像と音声を専用のマルチモーダルエンコーダーを介さずに処理できる点だと思われます。
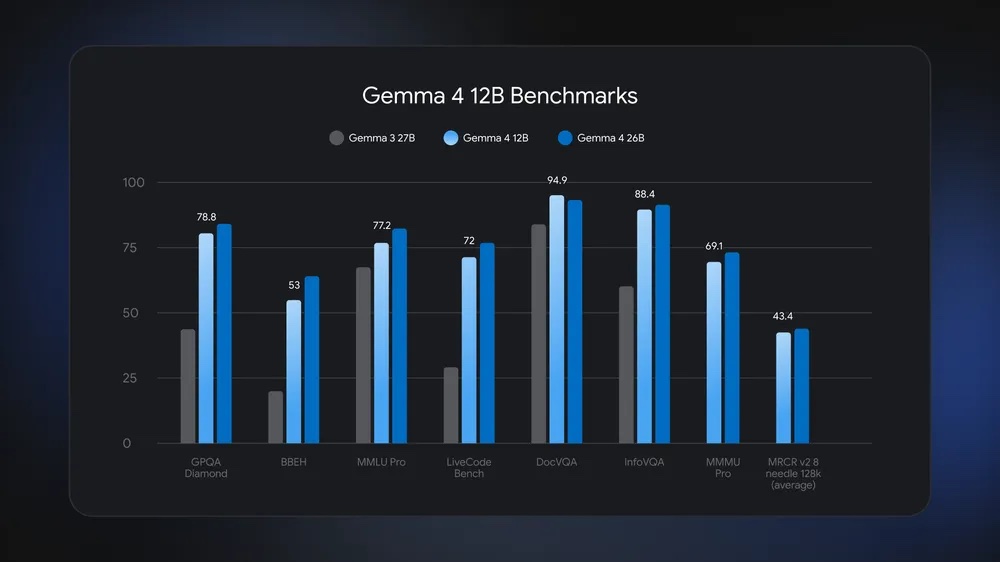
前者はGoogleが公開しているベンチマーク(上記画像参照)において、より大型の26B Moeモデルに匹敵するパフォーマンスを発揮していますが、メモリ使用量は半分以下であると説明されています。
特に後者は、画像と音声を別々のエンコーダーで変換してから言語モデルに渡すのが標準的であった為、その独自性が際立ちますね。
ネイティブ音声処理について
Gemma 4 12Bのネイティブ音声処理についてGoogleがデモ動画を公開しています。(macOS版Google AI Edge Eloquentを使用)
最後に
Google Gemma 4はLM Studio、Ollama、Google AI Edge Gallearyで試用することができます。
ソース・画像
Introducing Gemma 4 12B: a unified, encoder-free multimodal model(The Keyword)
