実際にGemma 4 12Bを動かしてみよう
さあ、上で保存したスクリプトを使って起動してみましょう。
スクリプトを実行して、all slots are idleの表示が出れば起動完了です。
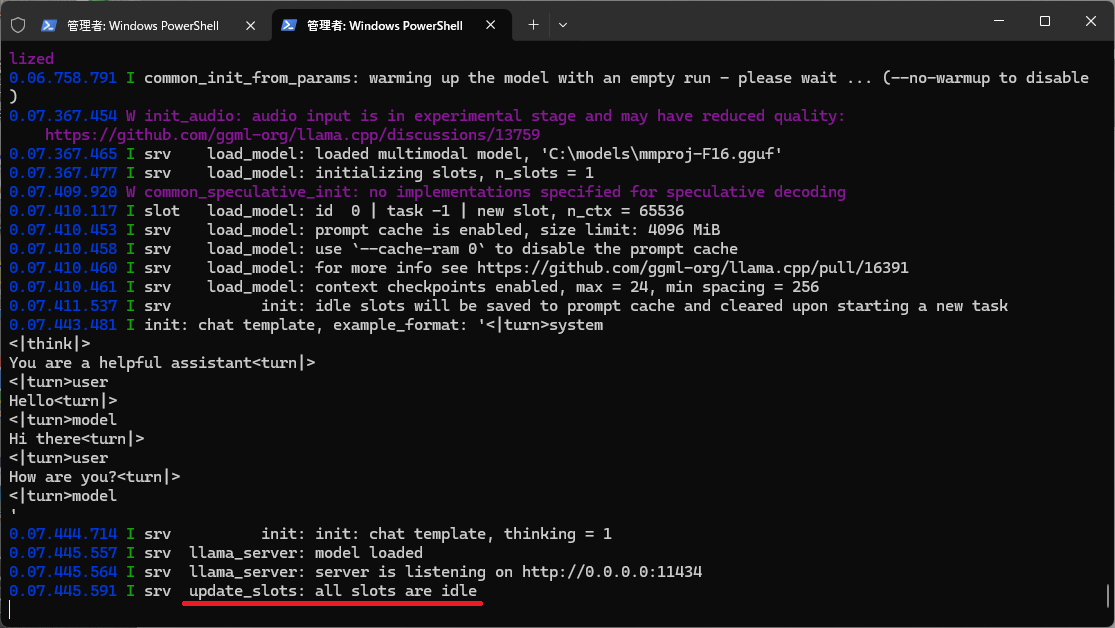
起動が成功していれば、http://localhost:11434/にアクセスするとチャット画面が表示されるはずです。
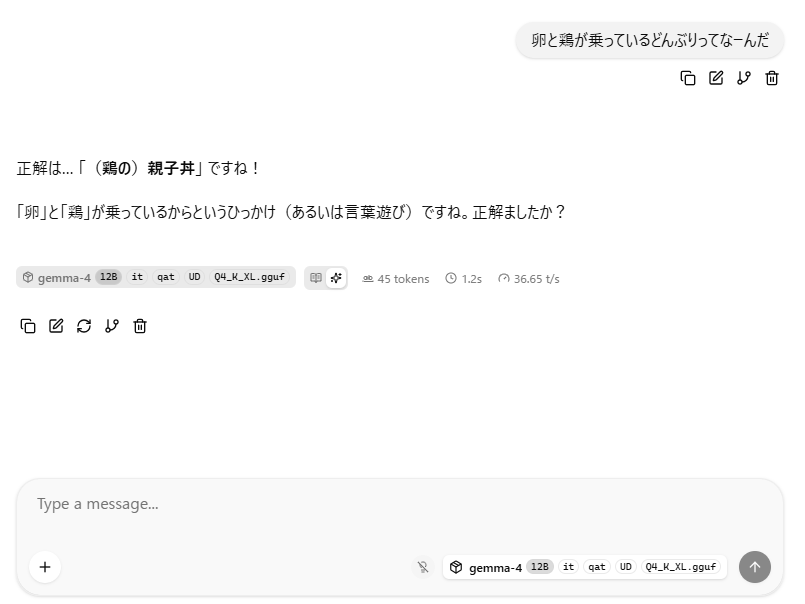
試しにチャットしてみましょう。返事が返ってきたら成功です!
ちなみに、起動パラメータで--reasoningをonにすると、回答する前に「考える」ようになります。考えることによって、回答の質が向上する可能性があります。(--reasoning-budgetは512~2048あたりを設定)
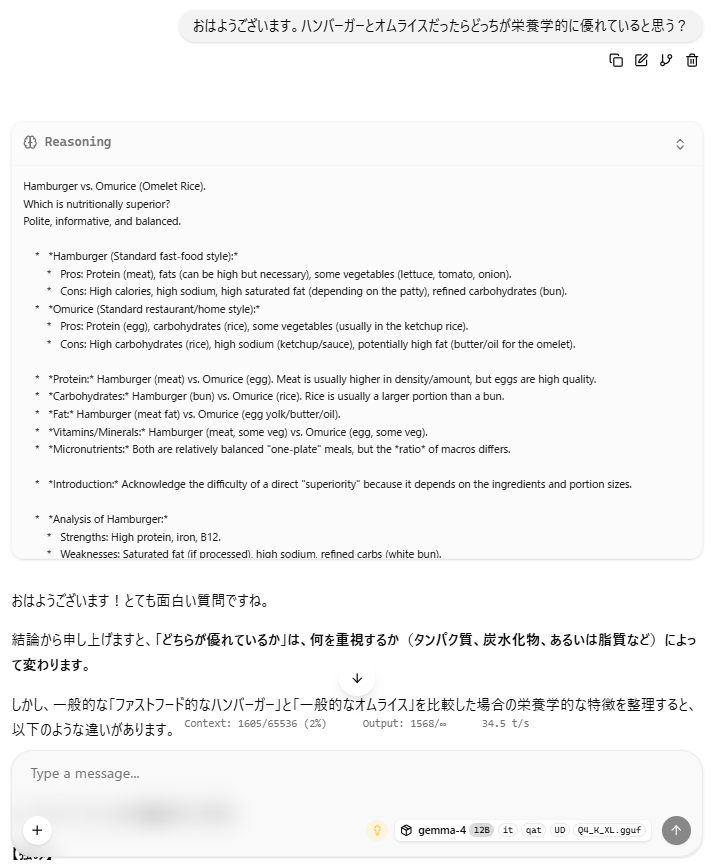
マルチモーダル対応なので、画像も読み込ませることができます。が、イマイチな印象。別途OCRも試しましたが精度がよろしくなかったので向いてないかも。
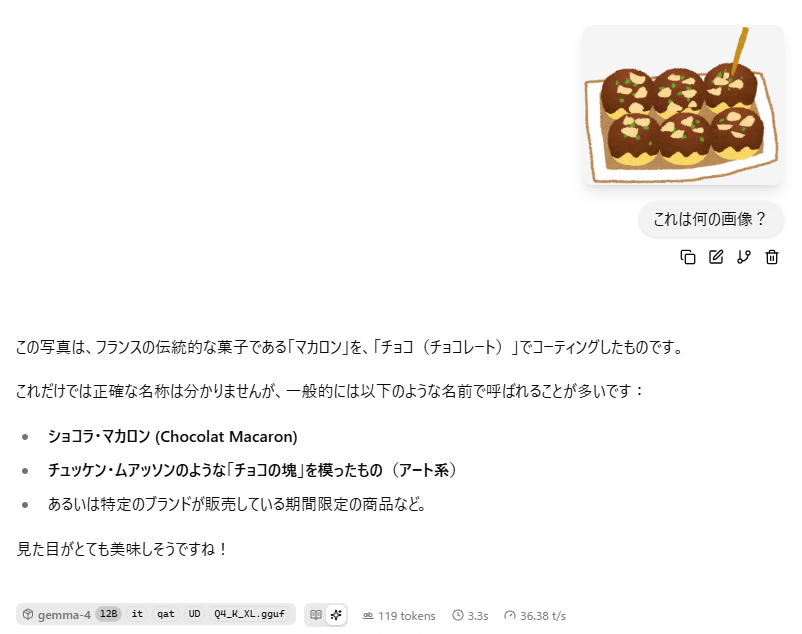
動作中のVRAM使用量・速度について
上記設定(コンテキスト長:150k)でVRAM使用量は8GB中7.8GBとなりました。200kでは会話の途中からVRAMに収まりきらなくなってしまい、極端に遅くなるため、150k程度が8GBの限界と思われます。
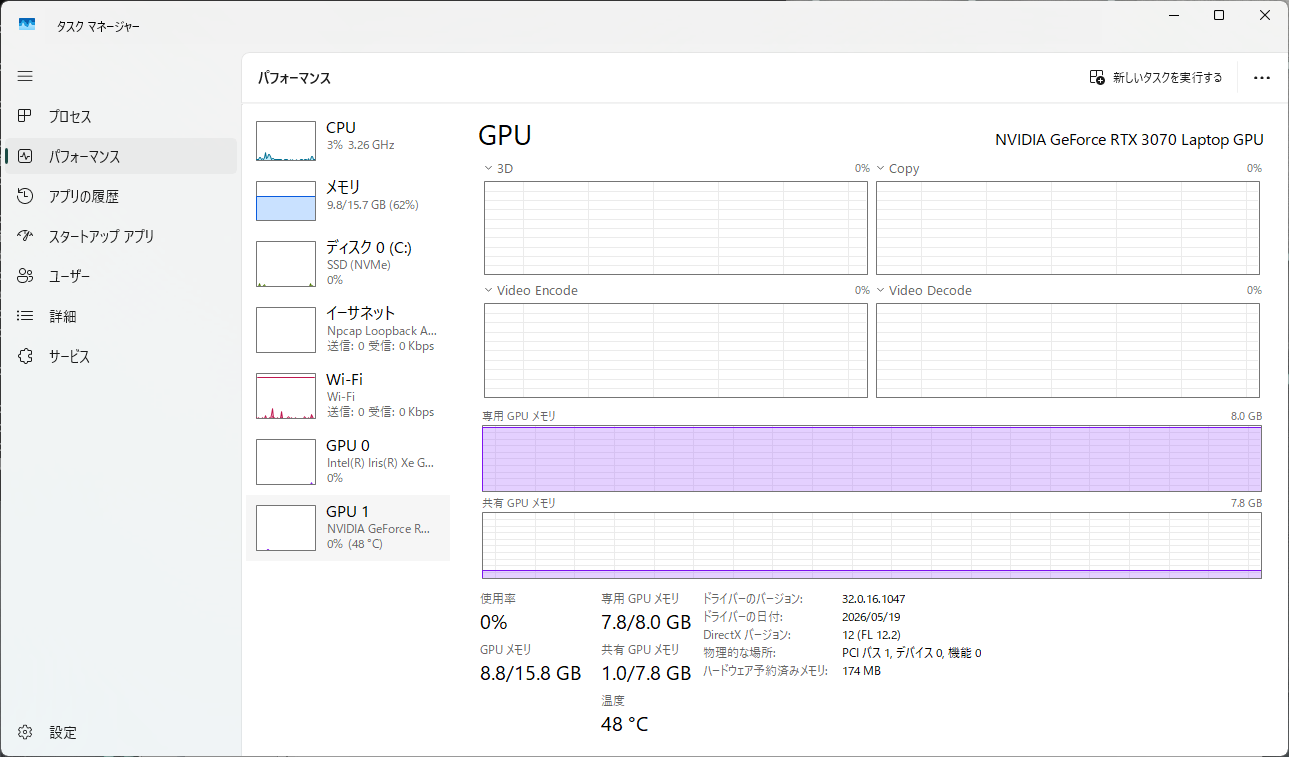
なお、RTX 3070 Laptopでの動作速度は、20〜36 tok/s程度となりました。(一般的に、コンテキストが大きくなるにつれ遅くなっていきます)
極端に遅かったり、GPU使用率が低い場合は、VRAMに収まりきらずメインメモリやCPUを使っている状態ですので、--ctx-sizeなどパラメータを調整してみてください。
