llama.cppの導入
llama.cppのリリースページから最新版のllama.cpp(b~~の数字が大きいもの)をダウンロードしてください。
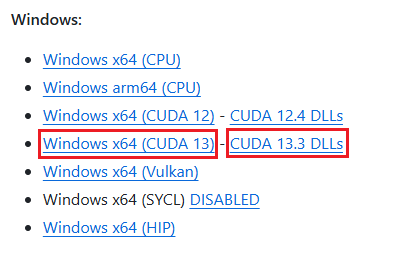
今回のRTX 3070 LaptopはCUDA 13.3に対応しているので、CUDA 13.3版とDLLをダウンロードします。
今回は説明のためにCドライブ直下にフォルダを作成します。(今回はb9553をダウンロードしたため、C:\llama-b9553-bin-win-cuda-13.3-x64\に保存しました)
DLLも同じフォルダにブチ込めばOK。
Gemma 4 12Bのダウンロード
llama.cppでローカルLLMを動かすには、モデルがGGUF形式である必要があります。
そのため今回はunslothが公開しているQAT版のGGUFを使用します。まあ、Gemma 4に限らずですが、unslothが公開しているGGUFを使うのが一般的ですね。
- モデルについて: unsloth/gemma-4-12B-it-qat-GGUF
- ダウンロードファイル:
gemma-4-12B-it-qat-UD-Q4_K_XL.gguf(モデル本体)mmproj-F16.gguf(マルチモーダル(画像・音声)対応用の追加ファイル)
Files and versionsページから上記2つをダウンロードしてください。
今回はC:\modelsフォルダに保存しました。\
起動スクリプト
本来であれば各種パラメータを理解したうえで、unslothのガイドなどを参考にパラメータを設定しますが、面倒だと思います。
ここに起動スクリプトを書いておくので、すぐに動かしたい方はこれを.ps1ファイルとして保存し、PowerShellで実行してください(フォルダ名などは適宜変更してください)。
& "C:\llama-b9553-bin-win-cuda-13.3-x64\llama-server.exe" `
-m "C:\models\gemma-4-12B-it-qat-UD-Q4_K_XL.gguf" `
--mmproj "C:\models\mmproj-F16.gguf" `
--jinja `
--ctx-size 150272 `
-ngl 99 `
-t 8 `
-np 1 `
--kv-unified `
--kv-offload `
--no-mmap `
-fa on `
--cache-type-k q4_0 `
--cache-type-v q4_0 `
--temp 0.7 `
--top-k 64 `
--top-p 0.95 `
--min-p 0.00 `
--repeat-penalty 1.3 `
--presence-penalty 0.0 `
--cache-ram 4096 `
--ctx-checkpoints 24 `
--reasoning-budget 0 `
--reasoning off `
--host 0.0.0.0 `
--port 11434主要パラメータの説明
| パラメータ | 説明 |
|---|---|
-m | モデル本体(GGUFファイル)を指定 |
--mmproj | マルチモーダル(画像など)用のモデルを指定 |
--ctx-size | コンテキスト長(処理できるトークンの量。増やすとVRAM使用量も増える) |
-ngl | GPUにオフロードするレイヤー数(99≒全てGPU) |
-t | 使用するCPUスレッド数 |
--cache-type-k--cache-type-v | KVキャッシュの量子化形式(VRAM節約のためq4_0) |
--reasoning | 推論のON/OFF。有効にすると回答を出力する前に「考える」。今回は速度重視でOFFとする |
--reasoning-budget | 推論に使用するトークンの最大量 |
--temp | 温度(低いほど一貫性のある回答、高いほど創造的な回答) |
--repeat-penalty | 繰り返しペナルティ(高いほど同じ表現の繰り返しを抑制) |
--host | 0.0.0.0にするとLANに公開。PC内でしか使用しない場合は127.0.0.1。 |
--port | 11434はOllamaのデフォルト値で、llamaをもじっているらしい(この値でなくても可) |
他にも多くのパラメータがありますが、ここでは割愛します。AIにでも聞いてください。なお、無限ループを回避するため、tempとrepeat-penaltyは推奨値から調整しています。


