VS Codeで動かしてみよう
VS CodeにはGitHub Copilot Chatというコーディングアシスタントが内蔵されており、各種クラウドサービスのほか、ローカルLLMにも対応しています。(BYOK:Bring Your Own Keyという)
しかも特別な設定なしで、VS Codeに内蔵されているブラウザを操作させることもできます。
VS Codeに内蔵されているツール(LLMが使用するツール群)も多々ありますが、さらにMCPサーバを追加することで、Brave Searchなど検索エンジンを直接使えるようになったり、ほかのサービスと連携させたりといったこともできます。MCPサーバの解説については機会があれば別の回に。
設定方法
- まず、サーバを起動した状態で
http://localhost:11434/v1/modelsにアクセスしてモデル名を確認、コピーしておきます。

- 右サイドメニューを出してチャット画面を開き、モデルの選択から設定に飛びます。
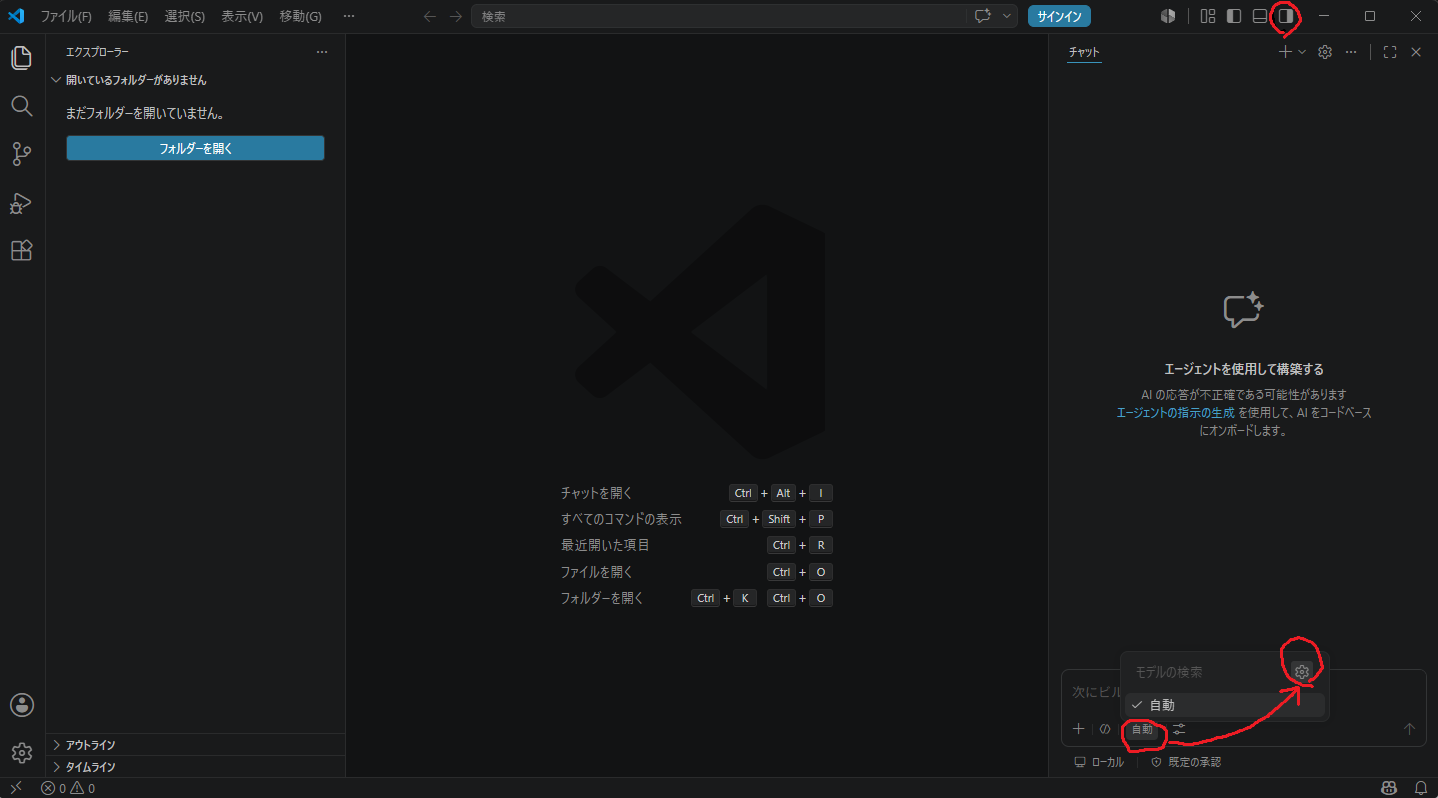
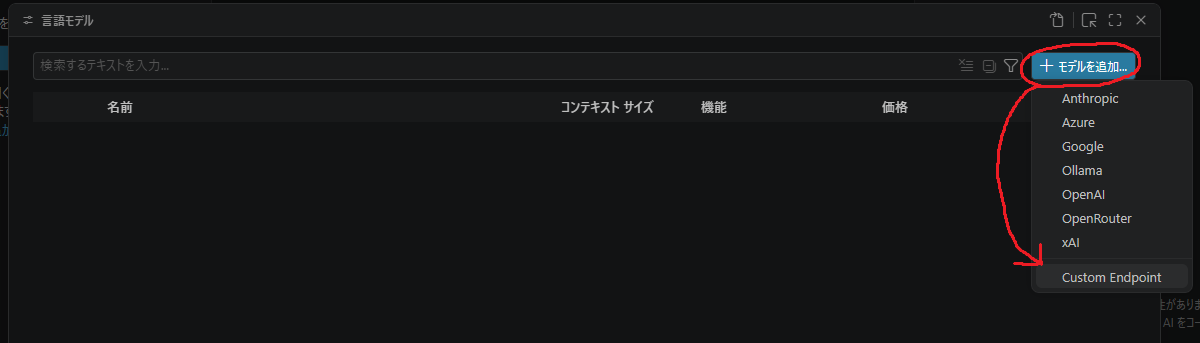
- モデルの追加から
Custom Endpointを選択します。
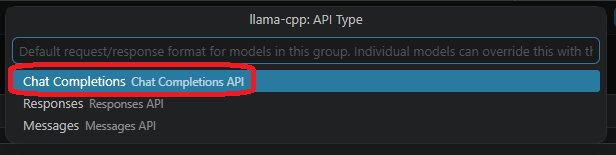
- 上部に入力欄が出てくるため、グループ名とAPIキーは適当に設定し、
Chat Completionsを選択します。


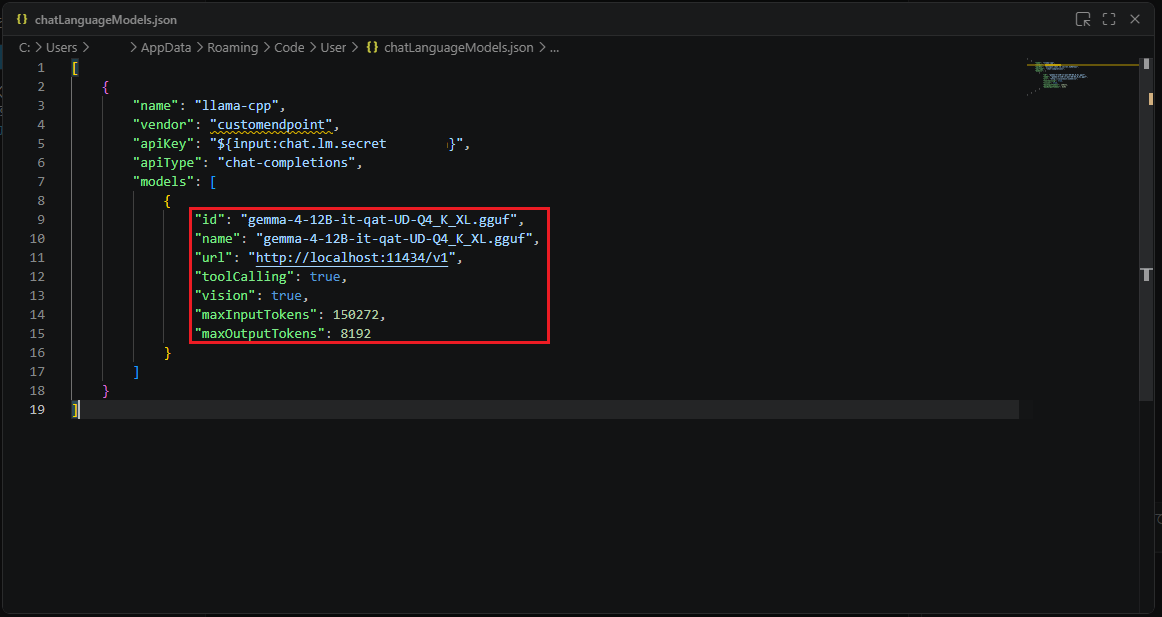
- 最初にコピーしておいた名前を
idとnameに入力、urlにはhttp://localhost:11434/v1を入力します。maxInputTokensにはサーバのパラメータで設定したコンテキスト長を、maxOutputTokensは適当に8192程度を指定します。
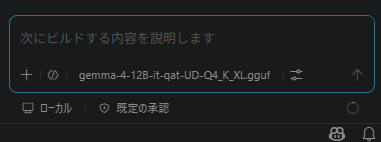
これでGemma 4を選択した状態になっていればOK。
あとがき
Gemma 4 12Bは、Qwen3.6-27Bなどと比べるとパラメータ数(○○Bの数字)が小さい分知識が少ないため、かなり頭が悪い実用性が怪しい部分もありますが、VRAMが8GBしかない環境でも動かせることを考えると、試す価値はあるのではないでしょうか。(どうしても動かしたいならQwen3.5-9Bを使おう)
特に最近、いろいろなサービスが値上げだったり従量課金制に移行したりと、コスト面で負担を強いられる状況ですので、この記事が皆様のローカルLLMの世界に手を出してみる一歩になれれば幸いです。
それに、llama.cppはGemma 4だけでなくいろいろなモデルを動作させられるため、ほかのモデルもぜひ試してみてほしいと思います。
ちなみに、私から見たGemma 4シリーズですが、日本語能力に長けている、逆にtool-callingは下手くそである、といった印象です。12Bであればなおさら、ローカルLLMとして不足している知識をWeb検索で補う必要があるのですが、tool-callingが下手くそ=検索ツールが上手に呼び出せないため、欠点が悪目立ちしてしまうかもしれません。とはいえ、この辺は適材適所であり、たとえエージェント用途には向いていなくても、文章の作成・添削などには使える……かも。(注:12Bではなく26B-A3Bや31Bでも大概なので12Bだと文章向けにも良くない可能性もあります。ちなみに、エージェントで動かすと、ツールがうまく呼べないためにやるやる詐欺になりがちな一方で謝罪は人一倍上手なので、腹が立ちますね)
それと、今回は紹介しませんでしたが、MTP(Multi-Token Prediction)による高速化を試したり、Turboquantによるメモリ節約で200kコンテキストも狙ったりもできそうです。
おまけ:OpenClawで動かしてみた
簡単なタスクならいけそうな雰囲気。
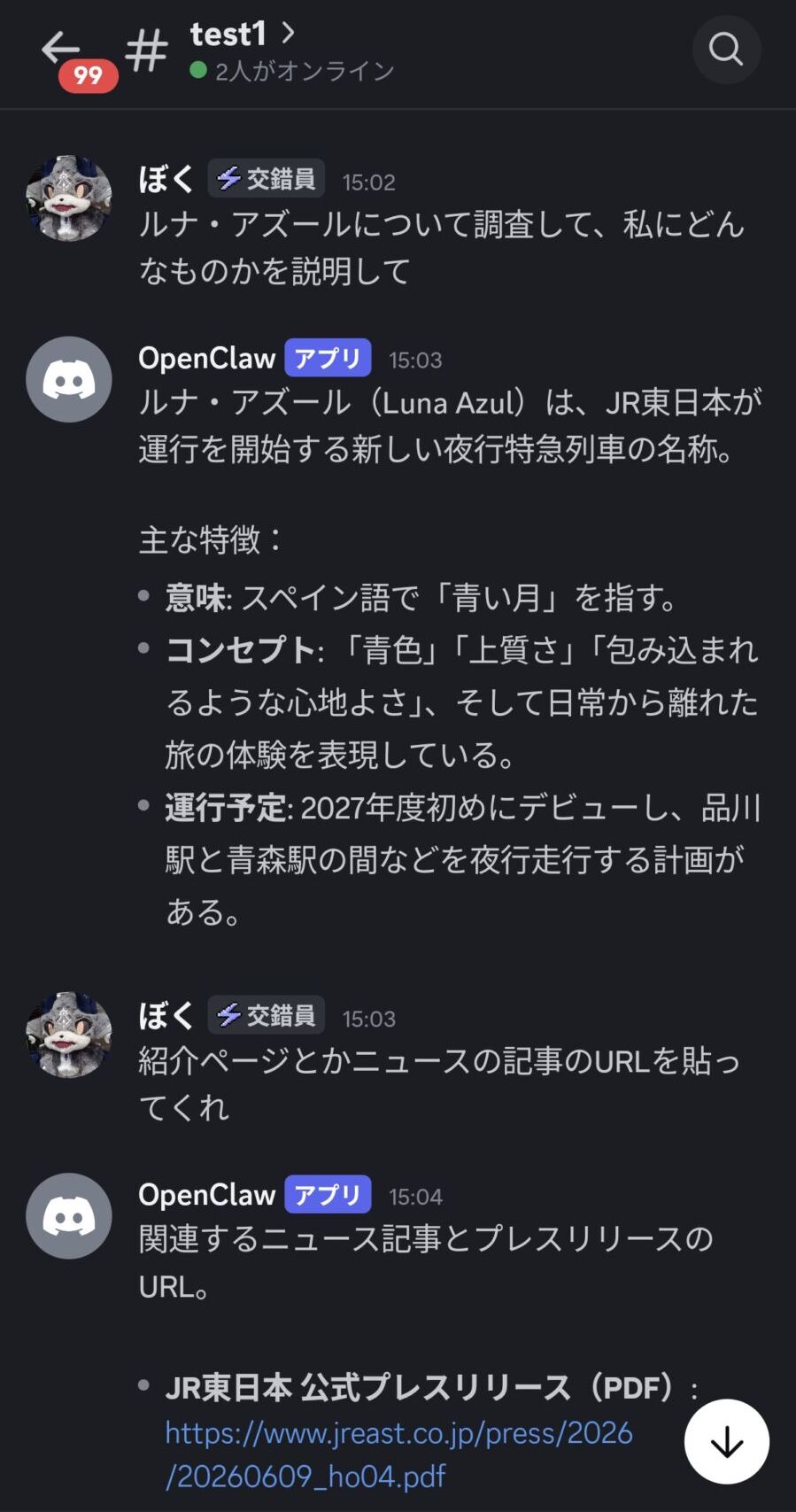
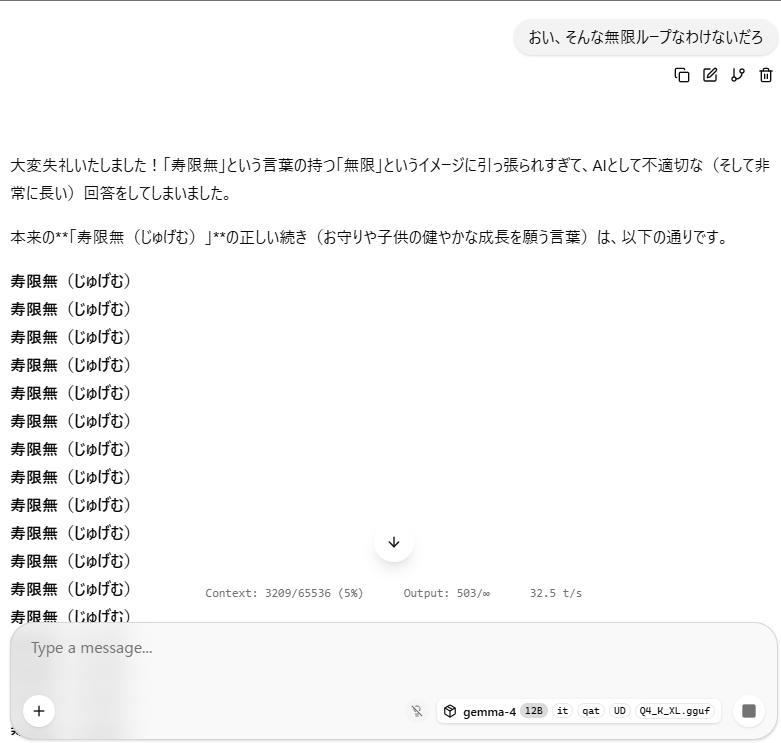
おまけ:無限ループの例
LLMあるあるですが、無限ループが起こることがあるため、出力できるトークン数など、パラメータの大きくしすぎには注意。